Architecting Autonomous Workflows: Implementing the Gemini Enterprise ADK on Google Cloud
AI systems are rapidly evolving from simple prompt-response tools into autonomous agents capable of planning, reasoning, and executing multi-step workflows. Organizations want LLM-powered systems that can not only generate content but also coordinate tasks, interact with APIs, and make context-aware decisions.
However, agentic workflows introduce real engineering challenges. LLMs don’t maintain state consistently, struggle with long contexts, and can produce incorrect reasoning if not carefully orchestrated. Without structure, a model can lose instructions, mis-handle tools, or hallucinate outputs during complex logic chains.
The Gemini Enterprise Agent Development Kit (ADK) provides the orchestration layer needed to bring reliability to these workflows. It bridges probabilistic model behavior with predictable system logic, allowing teams to build repeatable, production-ready processes on top of Gemini models.
Architectural Paradigm: From Single-LLM to Micro-agents
The ADK implements a modular design pattern, moving away from traditional Single-LLM workflows where one model and one system prompt attempt to handle all tasks and edge cases. This often results in context saturation, reduced instruction adherence, and unstable reasoning in complex workflows.
The ADK instead enforces a Micro-agent Architecture, decomposing complex objectives into isolated, specialized agents. This operates as a Hub-and-Spoke model, where a central Router or Root Agent maintains state and delegates work to ephemeral sub-agents (e.g., Retrieval, Analysis, Content Generation) via API hooks.
Technical Comparison: Single-LLM vs. ADK
The ADK introduces specific improvements in concurrency, state handling, and I/O operations.
FEATURE
SINGLE LLM WORKFLOW
ADK ORCHESTRATION
Context Management
Single Context Window: One long context window; harder to preserve instructions across steps.
Scoped Context: Root Agent keeps long-term state and passes clean, concise prompts to worker agents..
Concurrency
Serial Execution: one reasoning chain at a time.
Scatter-Gather Pattern: agents can run in parallel, reducing overall latency.
I/O Operations
Text-to-Text: Generates passive strings. No native ability to interact with the environment.
Function Calling: Native integration with OpenAPI specs. Agents invoke specific tools to perform CRUD operations on external databases and APIs.
Compute Strategy
Static Model Allocation: Utilizes high-parameter models for all tasks, resulting in inefficient compute usage.
Semantic Routing: Dynamically routes logic-heavy tasks to Gemini Pro and high-volume extraction tasks to Gemini Flash based on complexity scoring.
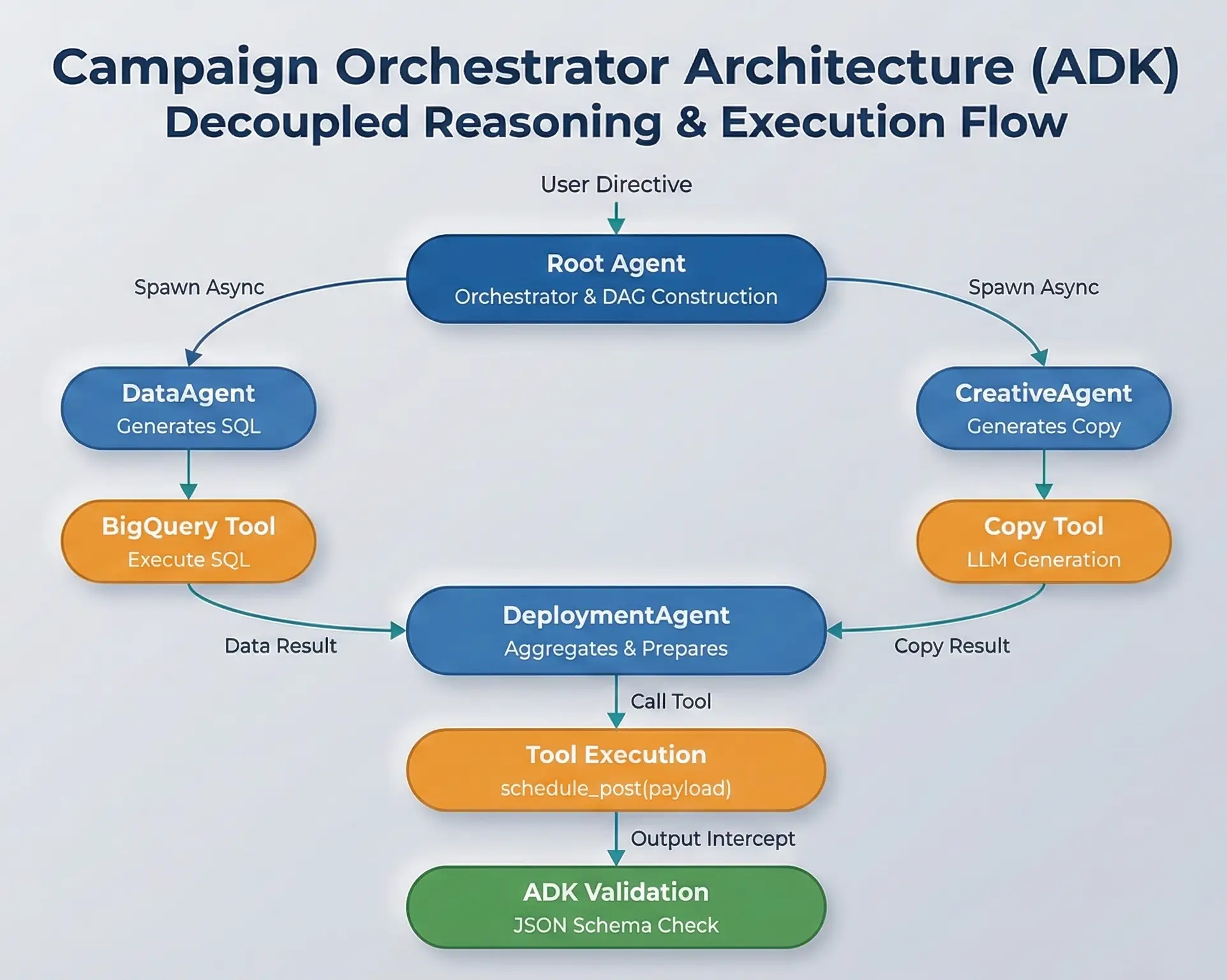
Technical Use Case: Asynchronous Campaign Orchestration
To illustrate the architectural advantages, consider a “Campaign Orchestrator” implementation. In a legacy script-based approach, logic is brittle. In the ADK, the “Reasoning Engine” (LLM) is decoupled from the “Execution Layer” (Tools), connected via a middleware layer.
The Workflow:
A Root Agent receives a high-level directive. Instead of attempting a single-shot completion, it constructs a Directed Acyclic Graph (DAG) of tasks:
Parallel Execution: The Root Agent spawns a DataAgent (generating BigQuery SQL) and a CreativeAgent (generating copy). These execute asynchronously to reduce total latency.
Tool Execution: The DeploymentAgent utilizes custom tools defined via Python functions (e.g., schedule_post(payload)).
State Validation: The ADK validates the tool output against a defined JSON schema before confirming success.
Engineering Challenges & ADK Solutions
1. Reliability & Governance
LLMs may generate incorrect tool arguments or hallucinate values.
ADK Approach: enforce schema validation (Pydantic/JSON) on all agent outputs before invoking tools or APIs.
2. Connecting to Legacy Systems
Enterprises often rely on older on-prem systems that don’t natively support modern LLM integrations.
ADK Approach: wrap SOAP or legacy endpoints inside Python functions and expose them as ADK tools, accessible through VPC service controls.
3. Latency & Cost Efficiency
Running everything on one large model increases compute usage.
ADK Approach: use dynamic routing—Gemini Pro for reasoning-heavy tasks and Gemini Flash for repetitive or extractive tasks.
Implementation Guidance
Keep agents focused. Narrow scopes make prompts cleaner and reduce reasoning drift.
Use async patterns. Parallelize network-bound tasks to improve user-perceived performance.
Structure API wrappers. Return well-structured JSON or DataFrames from tools to simplify downstream processing.<li?
Apply complexity routing. Use a simple complexity classifier to choose between Gemini Pro and Gemini Flash dynamically.
About Munvo
Munvo is a Google Cloud Premier Partner specializing in MarTech architecture and ML Ops. We assist enterprises in transitioning from experimental AI pilots to production-grade Vertex AI implementations, focusing on scalability, security, and measurable system throughput. To continue exploring the latest in enterprise AI, check out our other blog posts.
Ready to bring autonomous, production-grade AI workflows to your MarTech stack?
Connect with Munvo’s Google Cloud experts to architect, deploy, and scale agentic systems powered by the Gemini Enterprise ADK.
Google’s Gemini ADK enables reliable AI agent workflows by replacing single-LLM approaches with a modular micro-agent architecture.
Single-LLM workflows struggle with context overload, inconsistent state management, and hallucinations when handling complex tasks. The ADK solves this through a Hub-and-Spoke model where a central Router Agent delegates to specialized sub-agents that execute in parallel. This architecture provides scoped context management, native API integration with schema validation, and smart routing that assigns complex reasoning to Gemini Pro while using Gemini Flash for simple extraction tasks.
For example, a Campaign Orchestrator can have a Root Agent create a task workflow where DataAgent and CreativeAgent run simultaneously, then DeploymentAgent executes validated tools to schedule posts. This structured orchestration transforms unreliable LLM outputs into production-ready systems through modular design, async patterns for better performance, and schema validation that prevents errors before execution—ultimately optimizing both cost and compute efficiency.